



Performance impact of Citrix CVAD 2003




This post is meant as an introductory breakdown describing the high-level architecture and hardware setup of the basic components that are being used in the Citrix SD-WAN lab. This way everyone has the opportunity to replicate the lab setup and confirm or challenge our findings.
The setup consists of two Citrix SD-WAN hardware appliances. One 410 and one 1100. The 1100 is configured as the Master Control Node (MCN). The 410 is configured as the branch. Both appliances are orchestrated through Citrix SD-WAN Cloud.
Both appliances are staged with firmware version 11.0.2. Due to continuing development a different firmware can be used in future research. If so than this will be explicitly mentioned in the research.
Configuration of the appliances is completely standard with the only adjustments made for getting connectivity. The Citrix SD-WAN appliances are deployed in Gateway mode. This means that the Citrix SD-WAN appliance will be the router for the networks connected.
The connection used during the tests are two broadband connections. At the MCN side the broadband connection is a 250Mb download, 25Mb upload. At the branch the connection is a 150Mb download and 150Mb upload.
In the setup, bandwidth has been limited to 11Mb download and upload. This limit applies to the connection between the two Citrix SD-WAN appliances and between the Citrix SD-WAN at the branch and local internet breakout.
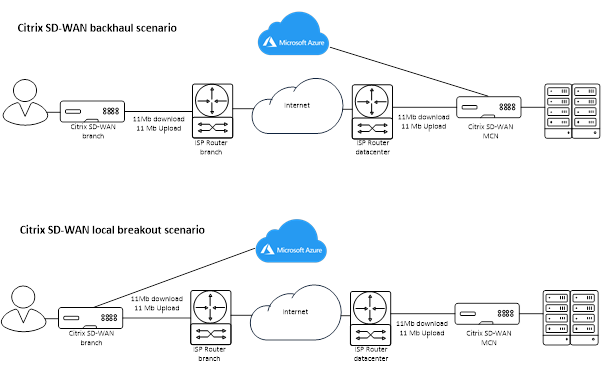
Above: the backhaul through Citrix SD-WAN virtual patch, below the local breakout through Citrix SD-WAN
For the performance research a uniform testing methodology is used so that the results can be replicated and benchmarking is done in the same way. This way results are reliable.
As a client a clean Windows 10 VM is used hosted on an Intel NUC6I5, default installation, antivirus off, optimized and updated.
Data files are created by a generator with random data. The files are of the following sizes:
For every file size there are 10 files of the same size in total and put within a corresponding folder on Microsoft OneDrive.
The downloading of files by the client is automated through PowerShell. The script will sign into Microsoft OneDrive, open the folder of one file sizes and start copying one of the data files. After every successful copy it will disconnect, sign into the file size folder and download the second data file. After this has been done for 10 times it will proceed to the next file size.
For every time a file is downloaded the following datapoints are collected within a csv.
Only valid data will be used in the researches. This means without any download failures during the run. In the research the average outcome of these datapoints are used.
Besides the above metrics also performance data is collected from the client.
Photo by Thomas Jensen on Unsplash

Echteld, Netherlands

Malta


